 alpha3166
alpha3166
ClearScanを試す その2
「その1」では、日本語・縦書きの新書にClearScanをかけてみましたが、こんどは英語・横書きの洋書ペーパーバックでどうなるか試してみます。先に結論を言ってしまうと、縦書きと違って、相当に実用的な仕上がりになりました。
元ファイルは、前回と同じくScanSnap S1500のスーパーファイン/カラー/圧縮率3の設定でスキャンした300dpiのPDFで、全部で517ページ、ファイルサイズは183MBです。判型が新書とだいたい同じなのに、1ページあたりのファイルサイズが倍ぐらいあるのは、紙がかなり茶色にヤケているのをカラーで取り込んだためと思われます。ペーパーバックって、紙質が悪くて、すぐに変色しちゃいますよね。
これを「OCRの言語=英語(アメリカ)、PDFの出力形式=ClearScan、画像のダウンサンプリング=最低(600dpi)」でOCRテキスト認識させたところ、処理に32分かかりましたが、ファイルサイズは19MBにまで小さくなりました。オリジナルの10分の1です。今回も、比較のため「PDFの出力形式=検索可能な画像」で普通のOCRもかけてみましたが、こちらは処理時間23分、できあがりのファイルサイズは129MBでした。
- オリジナル: 183MB
- 普通のOCR: 129MB(70%)、処理23分
- ClearScan: 19MB(10%)、処理32分
文字を拡大してみます。オリジナルだとこんな感じなのが――、

ClearScan後はこうなります。

まれに、やや文字がパラついて単語の区切りが分かりにくくなっている箇所がありますが、注意しなければ気づかないレベルです。この例では、オリジナルでこうだったのが――、
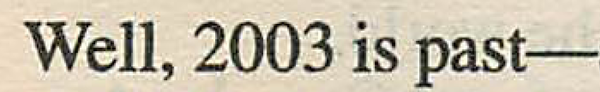
ClearScan後は “is” のあたりの文字間隔がちょっとおかしくなっているのが分かります。

イタリックや、サンセリフ系のフォントなんかも、元の形をきれいに保ってフォント化されています。オリジナル:

ClearScan後:

図の部分は画像のまま残っています。
実際にClearScan版をiPhone/iPadで数十ページ読んでみましたが、特に違和感はなく、ClearScan版なんてことはすぐに意識にのぼらなくなりました。それに加えて、ClearScan版は単語の選択がやりやすいという利点があることが分かりました。下記は、普通のOCR版をi文庫HDで開き、”twelve” という単語を長押しして選択した状態ですが、だいたいこのように狙った単語と少しずれた範囲が選択されてしまいます。

ところがClearScan版だと、9割方は狙った単語がビシッと選択されて、ePub版やKindle版を読んでいるときに近い感じです。私は本を読みながらしょっちゅう辞書を引くので、この差は結構重要です。

まとめると、ファイルサイズは10分の1で、読みやすさも問題なし、かつ単語の選択がラクにできるようになったりして良いことづくめ、逆にデメリットはほとんどないとないので、横書きのペーパーバックの場合は一律ClearScanにしてもよいかなと思える結果となりました。しかし、このあと思わぬ落とし穴が……。
ところで、この本は比較的最近自炊したので、紙の本がまだ手元に残っていました。そこで、最初から白黒でスキャンしてClearScanをかけるとどうなるかも試してみようと思いました。まずScanSnapの設定を白黒(600dpi)に変えてスキャンすると、ファイルサイズはカラーのときより大幅に小さい38MBとなりました。で、これにClearScanをかけたのですが、途中で「Paper Capture認識サービスのエラーにより、ページを処理できません。(5)」というエラーが出てしまいました。いちおうファイルは出力されているのですが、ファイルサイズは元ファイルと全く同じ、中身を見てもClearScanがかかっている様子はなく、要するに元ファイルがそのままコピーされただけの状態になっています。
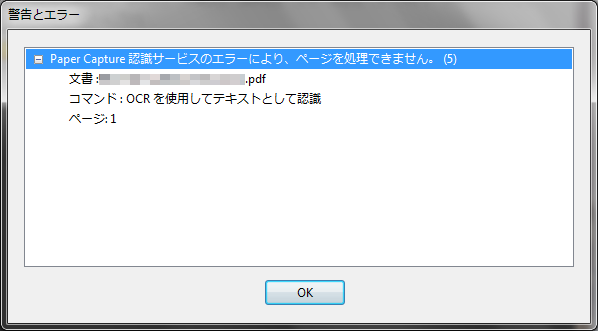
ページ1がエラーと出ているので、今度は対象ページから1ページ目を外してやってみましたが、200ページを超えたあたりでまた同じエラーが……。
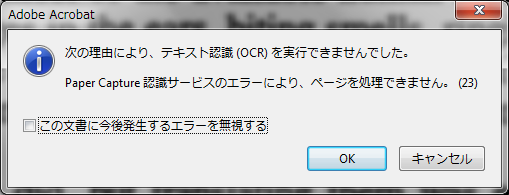
「この文書に今後発生するエラーを無視する」をチェックして「OK」を押すと、今度は「描画エラーが発生しました。」と言われて処理が終わってしまいました。
うーむ。ほんとは白黒+ClearScanでファイルサイズがどうなるかやってみたったんですが、「Paper Capture認識サービスのエラー」は原因も対処方法もはっきりしないようなので、とりえあずこのへんでギブアップ。1ページだけClearScanして、文字の具合だけ確かめておきましょう。白黒スキャン後の元ファイルはこんな感じ。

で、これにClearScanをかけるとこんな感じです。

紙のヤケが見えなくなって背景がスカッと白くなっているのと、文字のコントラストがはっきりして、やや太っているのがカラー版との違いでしょうか。こっちの方が好みという人はいそうな気がしますが、個人的にはこのベタッとして質感が失われた版面があまり好きではなくて、やっぱりカラー版の方が読みやすく感じてしまうので、白黒についてこれ以上の追求はしないでおくことにします。
で、この「Paper Capture認識サービスのエラー」ですが、これ、何も白黒に限って出るわけではなく、元ファイルがカラーの場合でも発生します。上で思わぬ落とし穴と書いたのはこのことです。手持ちの何冊かで試してみたところ、新書と同じサイズの11冊はすべて成功したのですが、それより大型の本14冊では僅か2冊しか成功せず、残りの12冊はエラーになってしまいました。さすがにこれだけ失敗率が高いと、使う気が失せて来ます。このあたり、Acrobat Xでは改善してたりするのでしょうか? だったら、多少お金を払ってでもバージョンアップするかもしれないんだけど……。
※バージョンメモ
- Adobe Acrobat 9 Standard 9.5.2
- i文庫HD 2.4.1