 alpha3166
alpha3166
Yahoo!ブログは何文字まで入力できるのか
Yahoo!ブログって、1つの記事の本文に何文字まで入力できるんでしょうか。
公式のヘルプを見ると、「全角で5,000文字(改行を含む)まで入力できます」と書かれています。しかし、最近では明らかに5,000文字を超えているような記事も投稿できるので、実際にはもっと多い気がします。また「全角で」5,000文字とありますが、じゃあ半角なら何文字までなの? とか、アクセント付きアルファベットだったら? とか、細かいところまではよく分かりません。

そこで、実際のところどうなのか、簡単に実験してみました(お急ぎの方は最後のまとめだけご覧ください)。
「a」は20,000個までOK
まず、ブログの投稿画面で、「a」を5,000個並べて本文に入力し(改行は無し)、確認ボタンを押してみると、これは当然ながら問題なくプレビュー画面が表示されました。この画面が出れば文字数制限はクリアしたとみなすことにします。続いて「a」を10,000個、15,000個、20,000個と増やしてみましたが、いずれも問題なくプレビューが表示されました。
25,000個にすると「内容は、最大20000文字です。」というダイアログが出て先に進めなくなりました。そこで、「a」を20,001個にしたところ、やはり「内容は、最大20000文字です。」のダイアログが出ました。
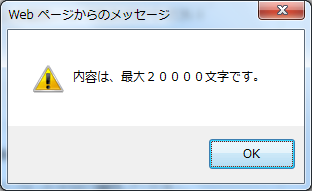
ということで、今の制限は「最大20000文字」で、いわゆる全角文字に限らず、ASCIIの範囲の文字でも1文字は1文字とカウントされるようです。
「あ」も20,000個までOK
続いてひらがなの「あ」を並べて試したところ、「a」と同様に20,000個ならOK、20,001個なら「内容は、最大20000文字です。」のエラーになりました。
「a」も「あ」も同じ1文字ということは、どうやらShift_JISなどではなく、Unicodeに基いて文字数を数えているようです。
追加漢字面の漢字は10,000個までOK
それなら、基本多言語面以外の文字ならどうかということで、追加漢字面の漢字として𠮷(土+口の”吉”、U+20BB7)を20,000個並べて試したところ、「内容は、最大20000文字です。」のエラーになりました。10,001個に減らしても同様にエラーです。10,000個にすると、プレビュー画面が表示されました(ただし、なぜか最後が「~𠮷𠮷𠮷𠮷𠮷𠮷𠮷&#」となっていて、10,000番目の𠮷だけ「&#」になっていました)。
この結果から、Unicodeの第1面から第16面の文字はサロゲートペアで2文字扱いにしていると思われ、UTF-16の16ビットのコードを1文字としてカウントしていると推測できます。
合成済みのéは20,000個までOKだが、eとアクセントを別に入力すると10,000個まで
続いてユニコード正規化の扱いを調べるため、アクセント付きアルファベットを並べて試してみました。
まず、「é」(U+00E9 Latin Small Letter E With Acute) の場合は20,000個までOK、20,001個だと「内容は、最大20000文字です。」のエラーになりました。
次に、「e」と「´」(U+0301 Combining Acute Accent) のペアを並べてみると、10,000個まではOK、10,001個だと「内容は、最大20000文字です。」のエラーになりました。
よって、文字数カウント時のユニコード正規化は行っていないようです。
「a」は2500個まで
ついでにHTMLの文字参照が何文字として数えられるのかも見ておきます。「a」の文字参照に当たる「a」が何個まで入力できるか調べたところ、2,500個まではOKで、2,501個だと「内容は、最大20000文字です。」のエラーになりました。
このことから、文字参照は単純にASCII文字としてそのままカウントされていることが分かります。
ただし、Yahoo!ブログの場合、最初の入力を文字参照で書いても、その記事を再度編集しようとすると実際の文字に変換されたものが出てくるので、データベースに格納する際に変換が実施されているのではないかと思います。
改行は1文字扱い
最後に、改行が何文字の扱いになっているのかを調べるため、まず「a」20,000個の途中に改行を1つ入れて「内容は、最大20000文字です。」のエラーにした状態で「a」を1個削除したところ、プレビュー画面に遷移したので、改行は1文字の扱いとなっているようです。
まとめ
- Yahoo!ブログの記事本文は最大20,000文字まで。
- ここでいう1文字は、UTF-16の16ビットのコードを1文字としてカウント。したがって、U+10000以降のサロゲートペアは1つで2文字の扱い。
- カウントの際にUnicode正規化は実施されない。
- 文字参照は、文字参照の記述を構成するASCIIの文字数でカウントされる。ただし、DBへは実際の文字に変換されて格納される。
- 改行は1つ1文字の扱い。