 alpha3166
alpha3166
Excelで2つの表を左右に並べてキーを揃える
やりたいこと
RDBのとあるテーブルにINSERT、UPDATE、DELETEを行い、その更新前後のデータをExcelシートの左右に並べて貼り付けて、変更箇所に色を付けたいとする。 左右でキーが同じレコードを同じ行に揃えられれば、あとは右側に条件付き書式をかけて、左と値が違うセルにだけ色が付くようにして完成だ。
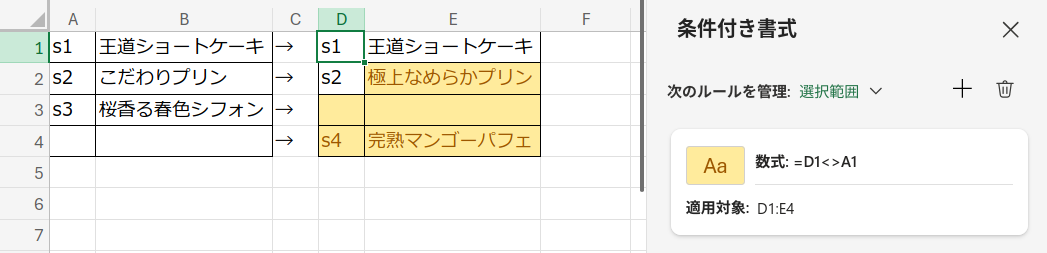
だが、この「キーが同じレコードを同じ行に揃える」というのが意外に面倒だったりする。 たとえば、左右どちらも1000行ずつくらいデータがあって、両方に存在する行 (UPDATEした)、左にだけ存在する行 (DELETEした)、右にだけ存在する行 (INSERTした) が入り混じっていると、手動で行を合わせていくのは現実的ではない。 Excelの関数だけで手軽に左右のキーを揃えるにはどうすればいいか。 いろいろ試してみた結果、今のところいちばん良さそうだと思った案をメモしておく。
アイデア
考え方として、左右それぞれに歯抜けの行はあるものの、全体としては「左のキー」と「右のキー」の和集合を縦に並べて、そのキーと一致するデータを左右それぞれに配置すればよい。 ただし、キーの和集合を目で見ながらひとつひとつ適切な場所に移動していくといった操作は、面倒なのでやりたくない。 そこで、左右それぞれに「このキーは歯抜けですよ」というダミーの行を末尾に足してやって、左右それぞれにキーでソートしてやる。 そうすれば、歯抜けも含めた総母数がキー順に並ぶので、結果的に左右で同じキーのレコードが同じ行に並ぶはずだ。
さてこのとき、左側の歯抜けの行というのは要するに、「左右のキーの和集合」から「左のキーの集合」を除いた差集合ということになる。 同様に、右側の歯抜けの行というのは「左右のキーの和集合」から「右のキーの集合」を除いた差集合だ。
つまり、Excelの関数だけでセルの和集合と差集合が簡単に作れるか、というのがこの方式のキモだ。
ひと昔前のExcelはこの手の集合演算が苦手だったように思うが、最近は便利な関数がいろいろ追加されており、意外と簡単に実現できてしまったりする。
先に言っておくと、VSTACK、UNIQUE、FILTER、COUNTIFS の4つの関数で実現できる。
実例
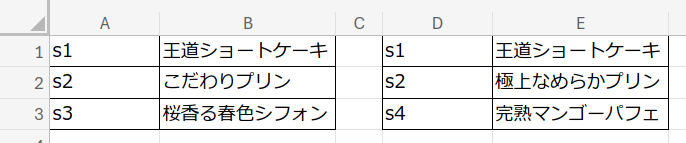
例として、商品コードと商品名からなる商品マスタの更新前後のデータを比較してみよう。
更新前のデータ
| 商品コード | 商品名 |
|---|---|
| s1 | 王道ショートケーキ |
| s2 | こだわりプリン |
| s3 | 桜香る春色シフォン |
更新後のデータ
| 商品コード | 商品名 |
|---|---|
| s1 | 王道ショートケーキ |
| s2 | 極上なめらかプリン |
| s4 | 完熟マンゴーパフェ |
見ての通り、
s1は更新なしs2は商品名をUPDATEs3はレコード自体をDELETEs4はレコード自体をINSERT
している。
更新前のデータを左側の A1:B3 に貼り付け、更新後のデータを右側の D1:E3 に貼り付けたところから始めよう。
和集合
まずは空いている列、例えばG列に、左右のキーの和集合を作る。
G1 セルに次の式を入れる。
=UNIQUE(VSTACK(A1:A3,D1:D3))
VSTACK というのは、引数で渡した複数の範囲を、縦に積み重ねて仮想的な範囲を生み出す関数で、内部的には
s1
s2
s3
s1
s2
s4
という配列が作られる。
UNIQUE というのは、引数の配列から重複を除いた配列を返す関数で、これによって
s1
s2
s3
s4
という配列が作られ、スピルによって G1:G4 に表示される。
これで G1:G4 に和集合が取り出せた。

差集合
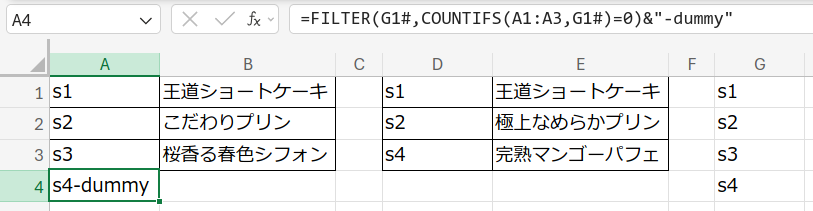
次に、左のデータの末尾の A4 セルに、「和集合にはあるが左にはないキー」、つまり差集合を抽出する式を入れる。
=FILTER(G1#,COUNTIFS(A1:A3,G1#)=0)&"-dummy"
この例だと
s4-dummy
が表示されるはずだ。
FILTER というのは、第1引数の範囲の中から、第2引数で指定した条件を満たすセルだけを取り出す関数だ。
第1引数の G1# のようにセルアドレスの末尾に # を付けると、そのセルのスピルで生成された配列全体を参照するという意味になる。
つまり G1# は、G1 セルに書いた =UNIQUE(VSTACK(A1:A3,D1:D3)) という式で生み出された和集合の G1:G4 を指定しているのと同じことになる (というか、式を入力するときに G1:G4 を選択すると、勝手に G1# に書き換わる)。
第2引数の「条件」に COUNTIFS を指定しているのは、やや直感的に理解しづらい部分かもしれない。
FILTER 関数のシンプルな使い方は、条件をリテラルで指定するケースだ。
例えば
=FILTER(G1:G4,G1:G4>="s3")
と書くと、G1:G4 の中で値が s3 以上のもの、つまり s3 と s4 が取り出される。
これは、内部的には G1 から G4 まで1セルずつ順番に取り出して、「セルの値>="s3"」が TRUE だったらその値を取り出す、というループ処理が行われているためだ。
そこで、取り出し条件を「COUNTIFS(A1:A3,G1:G4)=0」と書くと、G1 から G4 まで1セルずつ順番に取り出して、その値が A1:A3 に何個あるか数えて、1個もなかったらその値を取り出す、という意味になる。
結果的に、G1:G4 の中から A1:A3 にない値だけを取り出すことになる。
式の末尾の「&"-dummy"」は、実際には存在しないダミーキーを判別するマーカーだ。
あとでダミーキーを消すときに使う。
ここまでできたら、右のデータの末尾の D4 セルにも、「和集合にはあるが右にはないキー」を抽出する式を入れる。
=FILTER(G1#,COUNTIFS(D1:D3,G1#)=0)&"-dummy"

後処理
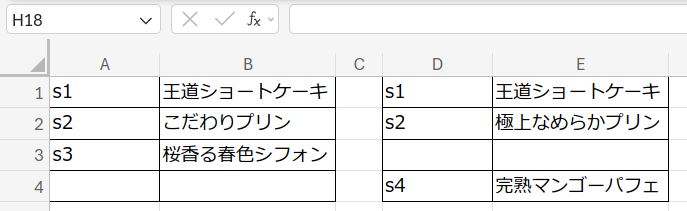
ダミーキーを選択してコピーし (Ctrl+C)、値のみ貼り付け (Ctrl+Shift+V) で固定してから、左右の表をそれぞれのキーでソートすると、同じキーのレコードが同じ行に並ぶ。

オートフィルタで -dummy が付いている行を左右それぞれに表示させ、その値を削除する。
あとは、右側に条件付き書式をかけて、左と値が違うセルにだけ色が付くようにすれば完成。
補足
キーが複数カラムからなる複合キーの場合でも、TEXTJOIN 関数などでいったんキー全体を1列にまとめてやれば、同じ考え方で行ける。